
On February 20, 2026, the Cloudflare BYOIP outage triggered a six-hour global service disruption that left customer applications unreachable from the internet. For CISOs, SOC analysts, and cloud architects, the incident serves as a critical case study in configuration risk, BGP route management, and operational resilience.
Unlike ransomware or a distributed denial-of-service (DDoS) attack, this outage was entirely self-inflicted — caused by an internal configuration bug that unintentionally withdrew approximately 1,100 customer BGP prefixes.
In this deep-dive analysis, we examine:
- What happened and why
- How BGP route withdrawals can cripple global connectivity
- The business and security implications
- Recovery challenges
- Best practices to prevent similar failures
- Compliance and resilience lessons for enterprise teams
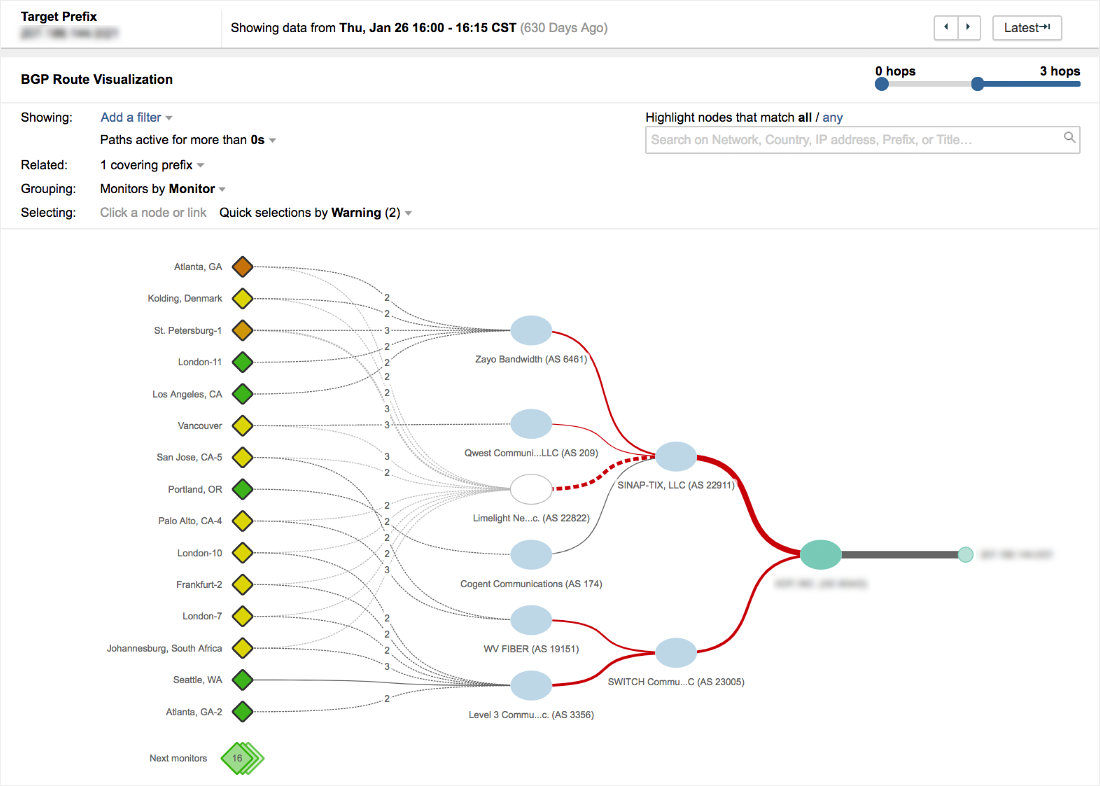
What Happened During the Cloudflare BYOIP Outage?


4
Cloudflare experienced a six-hour and seven-minute outage beginning at 17:48 UTC. The disruption affected customers using Bring Your Own IP (BYOIP) services.
Key Impact Highlights:
- 25% of all BYOIP prefixes globally were withdrawn
- Approximately 1,100 prefixes were deleted
- Core CDN and security services became unreachable
- Spectrum and Magic Transit customers experienced complete traffic failure
- 1.1.1.1 public DNS website returned HTTP 403 errors
- End users experienced timeouts and routing instability
Importantly, Cloudflare confirmed:
The outage was not caused by a cyberattack or malicious activity.
Instead, the incident originated from an internal Addressing API configuration error.
Understanding BYOIP and BGP: Why This Matters
What Is BYOIP (Bring Your Own IP)?
BYOIP allows customers to advertise their own IP address ranges through a cloud provider’s global network. This enables:
- IP portability across providers
- Consistent reputation management
- Reduced vendor lock-in
- Zero trust segmentation strategies
- Multi-cloud failover capabilities
For enterprises running regulated workloads, BYOIP ensures IP continuity across compliance zones.
How BGP Controls Internet Reachability

4
The Border Gateway Protocol (BGP) is the routing backbone of the internet. When prefixes are advertised:
- Traffic knows where to route
- Applications remain reachable
- CDN and security layers function normally
When prefixes are withdrawn:
- Routes disappear
- Traffic enters “BGP Path Hunting”
- Connections repeatedly search for a route
- Sessions eventually time out
This is exactly what happened.
Root Cause: Addressing API Bug
The incident traced back to a cleanup automation sub-task deployed under Cloudflare’s internal resilience initiative called Code Orange: Fail Small.
What Went Wrong?
An API query included the parameter:
pending_delete=
Because the flag was passed without a value, the server interpreted the empty string as a command to:
Queue all returned BYOIP prefixes for deletion.
Instead of removing a limited set of pending objects, the system systematically deleted ~1,100 prefixes and their service bindings.
Why This Is Dangerous
- Automated systems acted at machine speed
- No circuit breaker stopped abnormal deletion rates
- Configuration state and customer state were tightly coupled
- BGP withdrawals propagated globally
This was a control-plane failure, not a data-plane attack.
Impact Across Cloudflare Products
| Service | Impact Description |
|---|---|
| Core CDN & Security | Websites unreachable, connection timeouts |
| Spectrum | Traffic proxying failed completely |
| Dedicated Egress | Outbound traffic failures |
| Magic Transit | Protected apps unreachable |
| DNS (1.1.1.1 site) | HTTP 403 errors |
Business Implications
For enterprises, the outage likely resulted in:
- SLA violations
- Revenue disruption
- Incident response activation
- Reputational damage
- Regulatory risk in financial/health sectors
Why Recovery Took Six Hours
Outages involving BGP are complex because:
- Route re-advertisement takes time to propagate
- Some prefixes were only disabled
- ~300 prefixes lost all service bindings
- Global edge configuration redeployment was required
Timeline Overview
| Time (UTC) | Event |
|---|---|
| 17:56 | Broken sub-process executes |
| 18:46 | Engineer identifies and disables process |
| 19:19 | Dashboard self-remediation enabled |
| 23:03 | Global configuration fully restored |
Restoration required manual intervention and global machine configuration pushes — a reminder that automation failures often demand human recovery.
Security & Resilience Lessons for CISOs
1. Automation Without Guardrails Is a Risk Multiplier
DevOps acceleration increases blast radius if:
- Schema validation is weak
- Change management lacks staged deployment
- Circuit breakers are absent
- Observability lacks anomaly detection
2. Implement Control-Plane Protections
Best practices include:
- BGP prefix deletion rate monitoring
- Automated rollback on abnormal prefix withdrawal
- Immutable infrastructure patterns
- Canary deployments
- Operational state snapshots
3. Separate Configuration State from Deployment State
Modern cloud security architecture should:
- Isolate customer configuration from production rollouts
- Use transaction validation layers
- Implement change approval workflows aligned to NIST SP 800-53 CM controls
4. Strengthen Zero Trust at the Network Layer
Even internal systems require:
- Policy enforcement
- Privileged API governance
- Role-based access control (RBAC)
- Continuous monitoring
A zero trust model must apply to infrastructure automation — not just user access.
Mapping the Incident to MITRE & NIST Frameworks
Although not an attack, this outage aligns with risk categories addressed by major frameworks.
Relevant Controls
- NIST CSF – PR.IP-3: Configuration change control
- NIST SP 800-61: Incident response handling
- ISO/IEC 27001 A.12.1.2: Change management
- MITRE ATT&CK (Defense Evasion & Impact techniques) – Similar effects when routes are manipulated maliciously
Even non-malicious outages must be managed with the same rigor as a ransomware event.
Common Misconceptions About Cloud Outages
“If It’s Not a Hack, It’s Less Severe.”
False.
Internal configuration failures can:
- Create larger blast radii
- Bypass security monitoring
- Evade threat detection tools
“Cloud Providers Guarantee 100% Resilience.”
No provider is immune to:
- Human error
- Software bugs
- Automation misfires
- Control-plane misconfigurations
Shared responsibility still applies.
How Enterprises Can Reduce Similar Risks
Actionable Recommendations
- Conduct BGP dependency audits
- Implement multi-provider failover for mission-critical prefixes
- Enforce change freeze windows for high-impact updates
- Deploy automated anomaly detection on routing behavior
- Maintain incident runbooks for routing disruptions
- Simulate control-plane failures in tabletop exercises
Risk Impact Analysis
| Risk Factor | Severity |
|---|---|
| Availability Impact | Critical |
| Data Confidentiality | Low |
| Data Integrity | Low |
| Operational Risk | High |
| Compliance Risk | Medium to High |
This was primarily an availability incident, but in regulated sectors, downtime can trigger compliance investigations.
Expert Insight: The Hidden Risk of “Fail Small”
Cloudflare’s initiative aimed to reduce blast radius.
Ironically, automation intended to improve resilience amplified impact due to:
- Insufficient validation
- Lack of deletion safeguards
- Absence of rate-limit controls
Resilience engineering must include destructive-action controls.
FAQs
1. What caused the Cloudflare BYOIP outage?
An internal Addressing API bug misinterpreted an empty flag, triggering mass BGP prefix deletions.
2. Was the outage caused by a cyberattack?
No. Cloudflare confirmed it was an internal configuration error.
3. Why did websites become unreachable?
BGP route withdrawals caused traffic to enter path hunting mode, resulting in connection timeouts.
4. How long did the outage last?
Six hours and seven minutes.
5. How can organizations protect against similar incidents?
Implement change management controls, BGP monitoring, circuit breakers, and multi-provider redundancy.
6. Did the outage expose customer data?
No evidence suggests data compromise. The incident primarily affected availability.
Conclusion: A Wake-Up Call for Cloud Resilience
The Cloudflare BYOIP outage demonstrates that:
- Automation failures can rival cyberattacks in impact
- BGP remains a fragile yet critical internet dependency
- Configuration governance is a security priority
- Zero trust must extend to infrastructure automation
For CISOs and DevOps leaders, the takeaway is clear:
Resilience is not just about preventing attacks — it’s about preventing yourself from becoming the threat vector.
Now is the time to reassess routing dependencies, validate change management controls, and simulate infrastructure failure scenarios.